 von
von 
Hohe Korrelation als Indiz der Kausalität?
Die Argumentation, dass CO2 die mittlere globale Temperatur bestimmt, wird häufig mit diesem Diagramm, das eine starke Korrelation zwischen CO2-Konzentration und mittlerer globaler Temperatur zeigt, veranschaulicht oder sogar begründet, hier beispielsweise die in Maona Loa gemessene mittlere jährliche Konzentration und die jährlichen globalen Meeresoberflächentemperaturen:
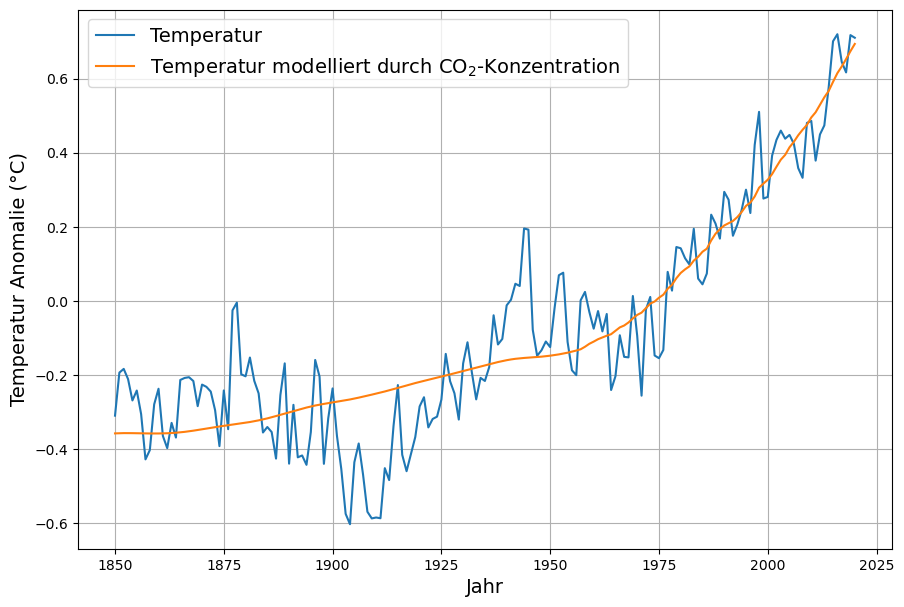
Es gibt zwar zwischen 1900 und 1975 — immerhin 75 Jahre — starke systematische Abweichungen, aber seit 1975 ist die Korrelation stark.
Wenn wir versuchen, mit den seit 1959 verfügbaren CO2-Konzentrationsdaten von Maona Loa die deutschen Mitteltemperaturen zu erklären, bekommen wir eine klare Beschreibung des Trends der Temperaturentwicklung, aber keine Erklärung der starken Schwankungen:
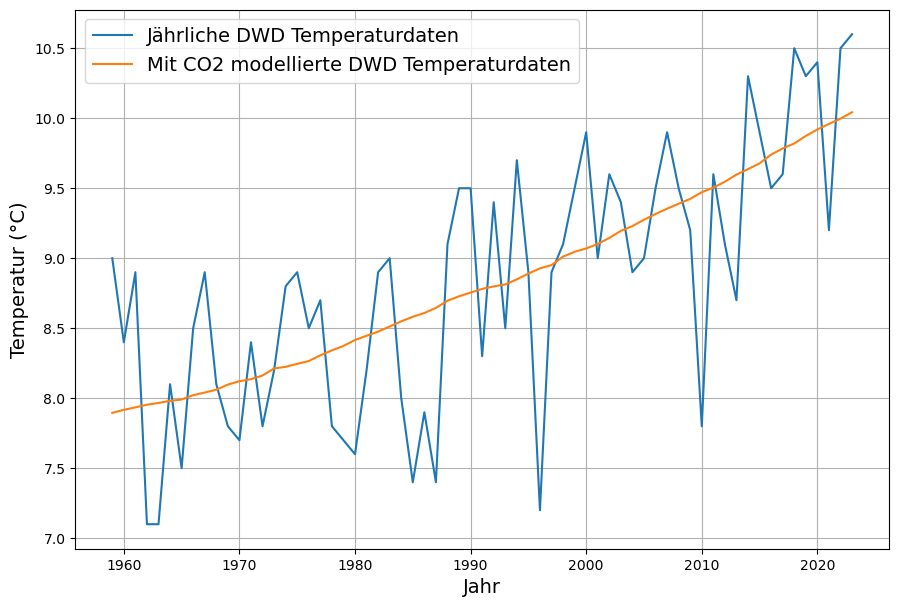
Die aus den im Jahr  gemessenen logarithmischen CO2-Konzentrationsdaten
gemessenen logarithmischen CO2-Konzentrationsdaten  mit der Methode der kleinsten Quadrate geschätzte „Modelltemperatur“
mit der Methode der kleinsten Quadrate geschätzte „Modelltemperatur“  ergibt sich als
ergibt sich als  (°C)
(°C)
Nehmen wir als 2. Erklärungsvariable die jährlichen Sonnenstunden hinzu, so verbessert sich die Anpassung etwas, aber wir sind noch weit entfernt von einer vollständigen Erklärung der schwankenden Temperaturen. Der Trend wird erwartungsgemöß ähnlich gut wiedergeben, auch ein Teil der Schwankungen wird mit den Sonnenstunden erklärt, aber bei weitem nicht so gut, wie man es eigentlich von einer kausalen Bestimmungsgröße erwarten würde :
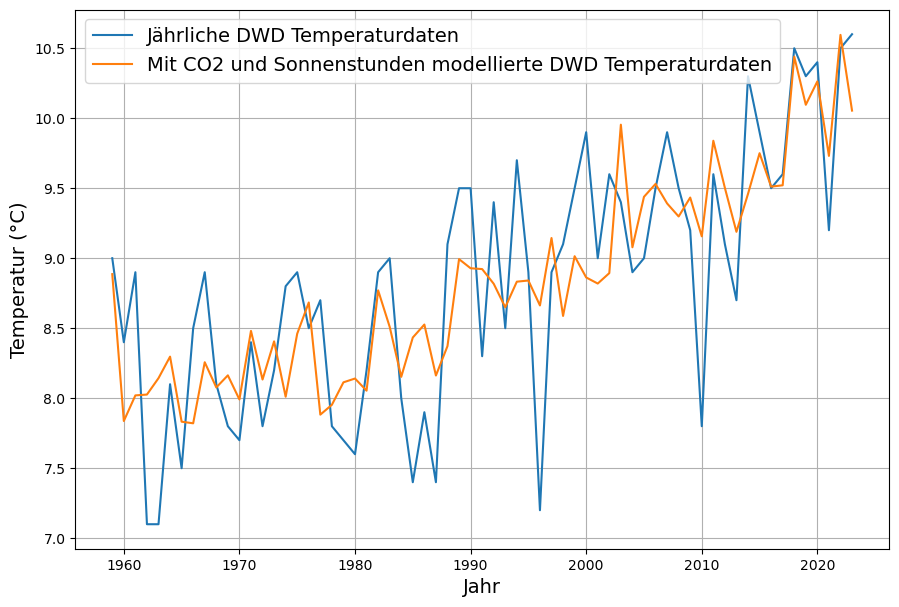
Die Modellgleichung für die geschätzte Temperatur wird mit der Erweiterung der Sonnenstunden  zu
zu (°C)
(°C)
Das relative Gewicht der CO2-Konzentration hat bei insgesamt verbessertem statistischem Erklärungswert der Daten etwas abgenommen.
Allerdings sieht es so aus, als ob das Zeitintervall 1 Jahr viel zu lang ist, um die Auswirkung der Sonneneinstrahlung auf die Temperatur korrekt zu behandeln. Es ist offensichtlich, dass die jahreszeitlichen Schwankungen unzweifelhaft von der Sonneneinstrahlung verursacht werden.
Die Auswirkungen der Einstrahlung sind nicht alle spontan, es müssen auch Speichereffekte berücksichtigt werden. Das entspricht unserer Wahrnehmung, dass die Wärmespeicherung der Sommerwärme 1-3 Monate anhält, und z.B. die wärmsten Monate erst nach der Zeit der größten Sonneneinstrahlung sind. Deswegen müssen wir ein auf dem Energiefluss beruhendes Modell erstellen, das mit monatlichen Messwerten gefüttert wird, und das eine Speicherung vorsieht.
Energieerhaltung – Verbesserung des Modells
Um das Verständnis zu verbessern, erstellen wir ein Modell mit monatlichen Daten unter Berücksichtigung der physikalischen Vorgänge (die Monate werden mit der Indexvariablen durchgezählt):
- Durch die Sonneneinstrahlung wird der Erdoberfläche Energie zugeführt, diese wird monatlich als proportional zur Zahl der Sonnenstunden angenommen,
- unter der Annahme des Treibhauseffekts wird ebenfalls Energie zugeführt, für die monatliche Energieaufnahme (bzw. verhinderte Energieabgabe) wird eine lineare Funktion von angenommen,
- die oberste Schicht der Erdoberfläche speichert die Energie und gibt sie wieder ab, die monatliche Abgabe wird als eine lineare Funktion der Temperatur
 angenommen,
angenommen, - die monatliche Temperaturänderung in Deutschland wird als proportional zur Energieänderung angenommen.
Daraus ergibt sich diese modellierte Bilanzgleichung, die Konstante  erlaubt es, beliebig skalierte Maßeinheiten zu verwenden:
erlaubt es, beliebig skalierte Maßeinheiten zu verwenden:
Auf der linken Seite der Gleichung steht die Temperaturveränderung als Repräsentant der Energiebilanzänderung, während die rechte Seite die Summe der Ursachen dieser Energieänderung darstellt.
Für die Bestimmung der Koeffizienten  mit der Methode der kleinsten Quadrate wird statt der modellierten Temperatur die gemessene Temperatur eingesetzt.
mit der Methode der kleinsten Quadrate wird statt der modellierten Temperatur die gemessene Temperatur eingesetzt.
Hier sind zunächst die monatliche Temperatur- und Sonnenstundendaten. Es ist erkennbar, dass die Temperaturdaten den Sonnenstundendaten um etwa 1-2 Monate hinterherhinken, aber insgesamt einen ähnlichen Verlauf haben:
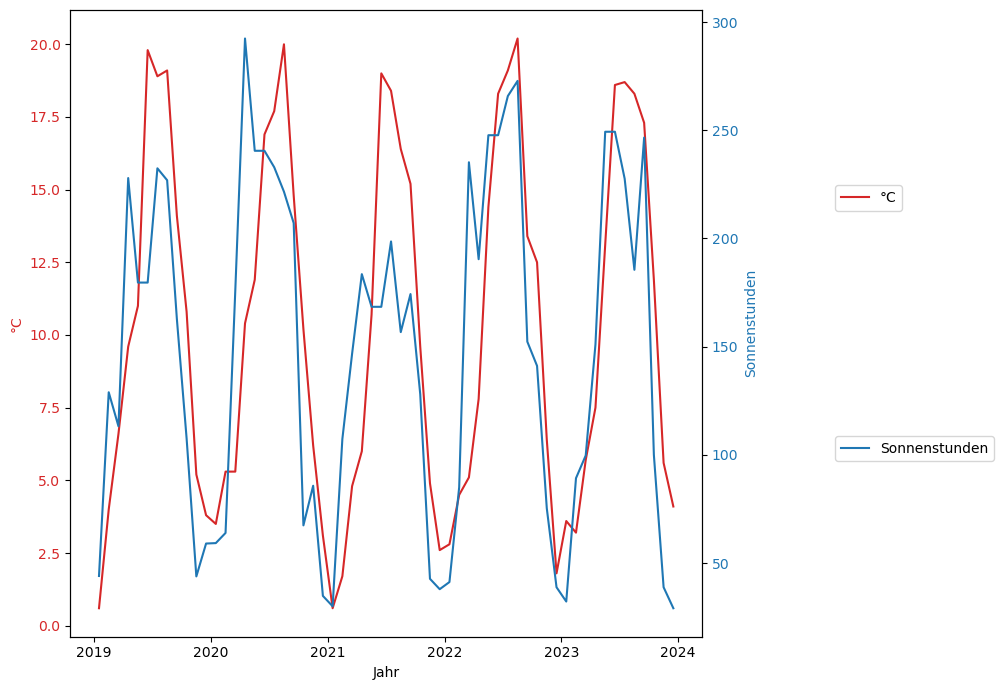
Dies passt zu der Annahme, dass wir tatsächlich einen Speichereffekt haben. Die Bilanzgleichung sollte also sinnvolle Werte liefern. Für die Auswertung des Schätzergebnisses müssen wir allerdings genauer hinschauen.
In dieser Darstellung sind in der 1. Spalte die Werte der jeweiligen Koeffizienten, in der 2. Spalte deren Standardfehler, danach die sogenannte T-Statistik, gefolgt von der Wahrscheinlichkeit, dass die Annahme des von 0 verschiedenen Koeffizienten falsch ist, der sogenannten Irrtumswahrscheinlichkeit. Das bedeutet, dass ein Koeffizient nur dann signifikant ist, wenn diese Wahrscheinlichkeit nahe 0 ist. Dies ist der Fall, wenn die T-Statistik größer 3 oder kleiner -3 ist. Die beiden letzten Spalten beschreiben schließlich das sog. 95% Konfidenzintervall. Das bedeutet, dass mit 95%-iger Wahrscheinlichkeit sich der tatsächliche Schätzwert innerhalb dieses Intervalls befindet.
Koeffizient Std.Fehler t-Wert P>|t| [0.025 0.975]
--------------------------------------------------------------------
a -0.4826 0.0142 -33.9049 0.0000 -0.5105 -0.4546
b 0.0492 0.0013 38.8127 0.0000 0.0467 0.0517
c 0.6857 0.9038 0.7587 0.4483 -1.0885 2.4598
d -6.3719 5.3013 -1.2020 0.2297 -16.7782 4.0344
Hier sind die Irrtumswahrscheinlichkeiten der Koeffizienten  und mit 45% bzw. 23% dermaßen groß, dass wir daraus schließen müssen, dass sowohl
und mit 45% bzw. 23% dermaßen groß, dass wir daraus schließen müssen, dass sowohl  also auch
also auch  sind. misst die Bedeutung der CO2-Konzentration für die Temperatur. Das bedeutet, dass in Deutschland seit 64 Jahren die CO2-Konzentration keinen statistisch signifikanten Einfluss auf die Temperaturentwicklung hat. Dies aber ist der Zeitraum der größten anthropogenen Emissionen der Geschichte.
sind. misst die Bedeutung der CO2-Konzentration für die Temperatur. Das bedeutet, dass in Deutschland seit 64 Jahren die CO2-Konzentration keinen statistisch signifikanten Einfluss auf die Temperaturentwicklung hat. Dies aber ist der Zeitraum der größten anthropogenen Emissionen der Geschichte.
Dass ebenfalls den Wert 0 annimmt, ist eher dem Zufall geschuldet, denn diese Konstante hängt von den Maßeinheiten der CO2-Konzentration und der Temperatur ab.
Demzufolge wird die Bilanzgleichung angepasst: 
mit dem Ergebnis:
Koeffizient Std.Fehler t-Wert P>|t| [0.025 0.975]
--------------------------------------------------------------------
a -0.4823 0.0142 -33.9056 0.0000 -0.5102 -0.4544
b 0.0493 0.0013 38.9661 0.0000 0.0468 0.0517
d -2.3520 0.1659 -14.1788 0.0000 -2.6776 -2.0264
Hier ist nun die Konstante aufgrund des Umstandes, dass ist, wieder mit hoher Signifikanz gültig. Die beiden anderen Koeffizienten  und
und  haben sich kaum verändert. Sie verdienen eine kurze Diskussion:
haben sich kaum verändert. Sie verdienen eine kurze Diskussion:
Der Koeffizient gibt an, welcher Teil der als Temperatur gemessenen Energie im Laufe eines Monate wieder abgegeben wird. Das ist fast die Hälfte. Dieser Faktor ist unabhängig vom Nullpunkt der Temperaturskala, bei der Wahl von K oder Anomalien statt °C käme derselbe Wert heraus. Der Wert entspricht etwa dem subjektiven Empfinden, wie sich im Sommer die Zeiten größter Temperatur zeitlich gegenüber dem Maximum der Sonneneinstrahlung verschieben.
Der Koeffizient gibt an, mit welchem Faktor sich die Sonnenstunden in monatliche Temperaturänderung übersetzen.
Das Ergebnis ist nicht nur eine abstrakte Statistik, es lässt sich auch veranschaulichen, indem der monatliche Temperaturverlauf der letzten 64 Jahre mit Hilfe des beschriebenen Modells rekonstruiert wird.
Die Rekonstruktion des gesamten Temperaturverlauf ergibt sich aus der Zeitreihe der Sonnenstunden und einem einzigen Temperatur-Startwert  , dem Vormonat des Beginns der untersuchten Zeitreihe seit 1959, also hier vom Dezember 1958.
, dem Vormonat des Beginns der untersuchten Zeitreihe seit 1959, also hier vom Dezember 1958.
Die Rekonstruktion erfolgt mit dieser Rekursion aus den Sonnenstunden über die 768 Monate vom Januar 1959 bis Dezember 2023:

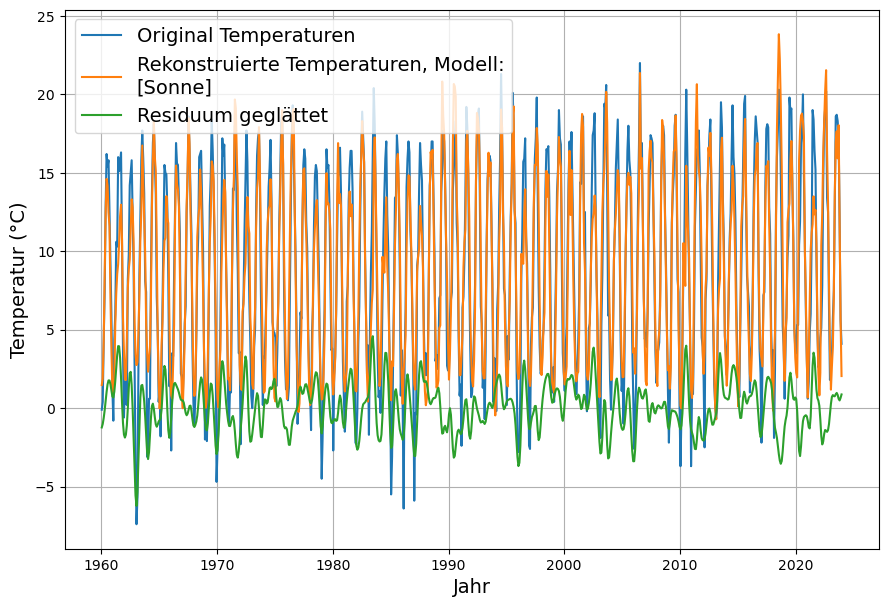
Hier die vollständige Rekonstruktion der Temperaturdaten im Vergleich der Original-Temperaturdaten:
Der deutlicheren Darstellung wegen werden die letzten 10 Jahre vergrößert dargestellt:
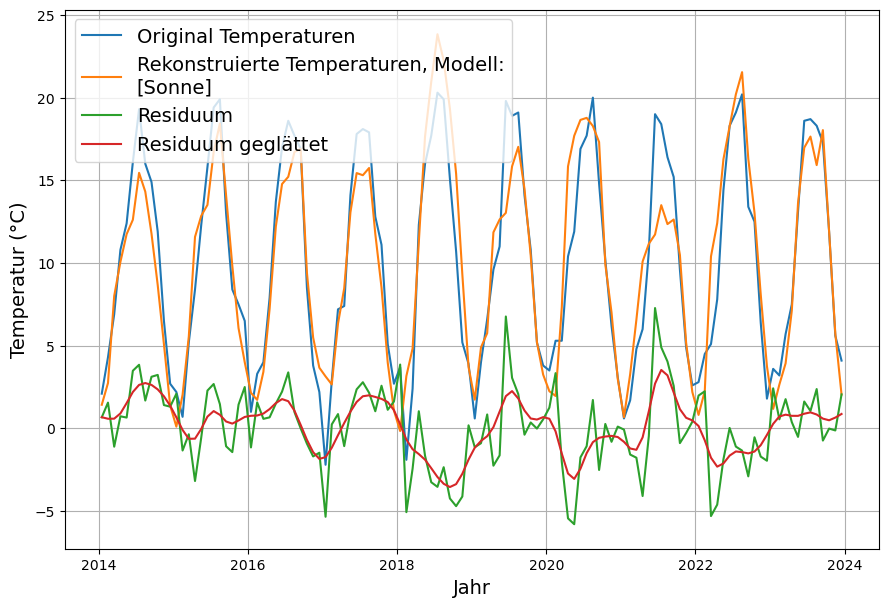
Es fällt auf, dass das Residuum, d.h. die Abweichungen der Rekonstruktion von den tatsächlichen Temperaturen bis zum Ende des untersuchten Zeitraums um 0 herum symmetrisch erscheint und keine offensichtlichen systematischen Abweichungen zeigt. Das Maß des Fehlers der Rekonstruktion ist die Standardabweichung des Residuums. Diese beträgt 2.5°C. Da wir einen langen Zeitraum von 64 Jahren untersuchen, könnte eine Feinanalyse der langfristigen Trends von Original-Temperaturen, Rekonstruktion und Residuum eine mögliche Obergrenze des möglichen Einflusses von CO2 finden.
Feinanalyse des Residuums
Wenn wir von den 3 Kurven Originaltemperaturdaten, Rekonstruktion und Residuum über den ganzen 64-Jahre Zeitraum die mittlere Steigung durch Schätzung einer Ausgleichsgeraden bestimmen, bekommen wir folgende langfristige Werte:
- Originaltemperaturdaten: 0.0027 °C/Monat = 0.032 °C/Jahr
- Rekonstruierte Temperaturdaten: 0.0024°C/Monat = 0.029 °C/Jahr
- Residuum: 0.00028 °C/Monat = 0.0034 °C/Jahr
Vom Trend der Originaltemperaturen werden 90% durch die Zahl der Sonnenstunden erklärt. Für weitere Ursachen bleiben also nur noch 10% an nicht erklärter Variabilität übrig. Bis zum Beweis des Gegenteils können wir also annehmen, dass höchstens für diese 10% der Anstieg der CO2-Konzentration verantwortlich ist, also für maximal 0.03° C pro Jahrzehnt während der letzten 64 Jahre. Statistisch kann aber der Beitrag der CO2-Konzentration nicht als signifikant beurteilt werden.
Zu bedenken ist, dass mit diesem einfachen Modell sehr viele Einflussfaktoren und Inhomogenitäten nicht berücksichtigt sind, dass also der Einfluss der CO2-Konzentration nicht der einzige Faktor ist, der zusätzlich zu den Sonnenstunden wirksam ist. Deswegen wird der CO2 Einfluss ja auch als statistisch nicht als signifikant bewertet.
Erweiterung — Korrektur durch Approximation der tatsächlichen Einstrahlung
Bislang haben wir die Sonnenstunden als Repräsentant des tatsächlichen Energieflusses verwendet werden. Das ist nicht ganz korrekt, denn eine Sonnenstunde im Winter bedeutet aufgrund des viel flacheren Einfallswinkels deutlich weniger eingestrahlte Energie als im Sommer.
Der jahreszeitliche Verlauf der Wichtung des einströmenden Energieflusses hat diese Form. Mit dieser Wichtung müssen die Sonnenstunden multipliziert werden, um den Energiefluß zu erhalten.
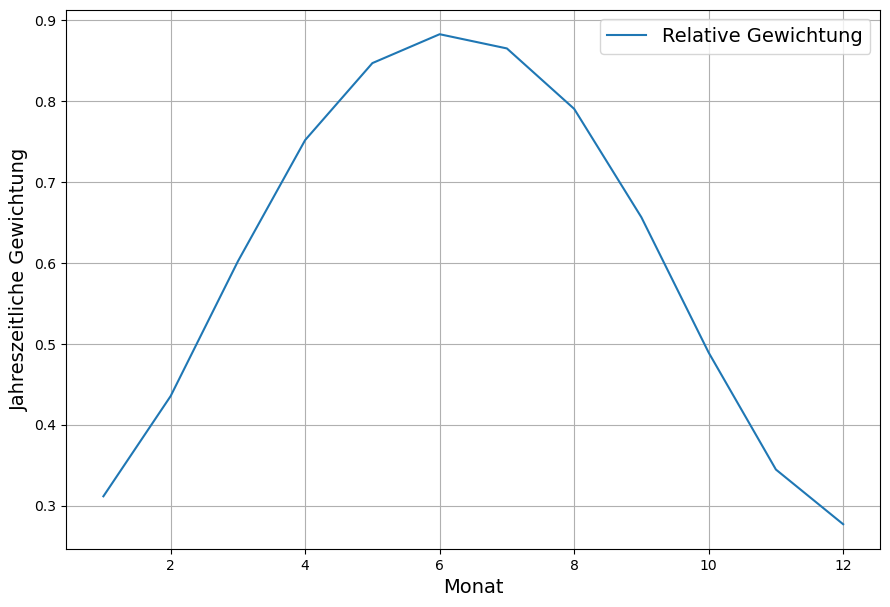
Mit diesen monatlichen Wichtungen wird das Modell aus Sonneneinstrahlung und CO2 erneut bestimmt. Wiederum muss der Beitrag des CO2 wegen mangelnder Signifikanz abgelehnt werden. Daher hier die Rekonstruktion der Temperatur aus dem einstrahlenden Energiefluss etwas besser als die obige Rekonstruktion.
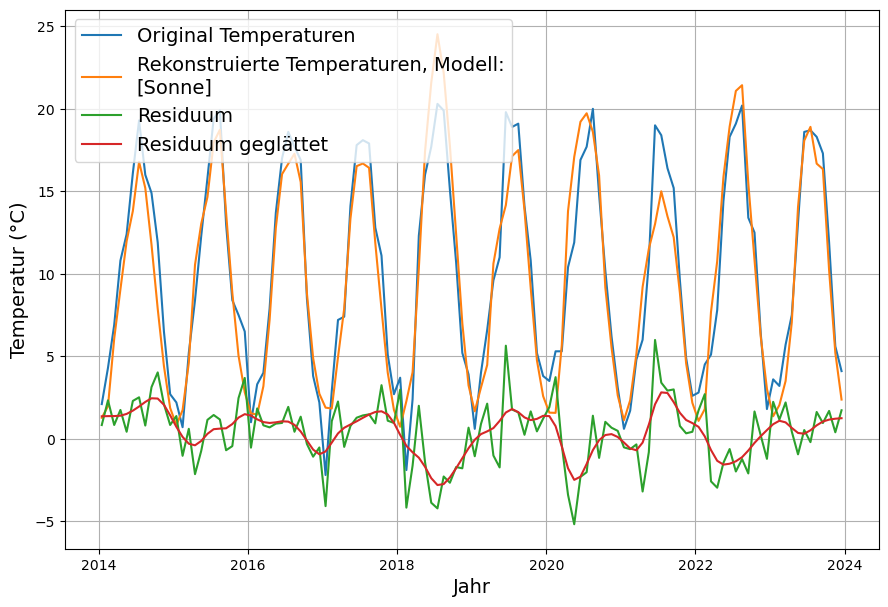
Durch die Korrektur der Sonnenstunden zum Energiefluss hat sich der Standardabweichung des Residuums auf 2.1°C verringert.
Mögliche Verallgemeinerung
Weltweit ist die Erfassung der Sonnenstunden weitaus weniger vollständig als die der Temperaturmessung. Daher können die Ergebnisse für Deutschland nicht einfach weltweit reproduziert werden.
Aber es wird mit Satelliten die Wolkenbedeckung bzw. die Reflexion der Sonneneinstrahlung an den Wolken gemessen. Mit diesen Daten kommt man zu ähnlichen Ergebnissen, dass nämlich der Anstieg der CO2-Konzentration allenfalls für 20% der weltweit mittleren Temperaturerhöhung verantwortlich ist. Da diese im Schnitt niedriger ist als die Temperaturerhöhung in Deutschland, führt das am Ende ebenfalls zu einer Obergrenze von 0.03°C pro Jahrzehnt für die Folgen des CO2-bedingten Treibhauseffekts. Das ist wiederum konsistent mit der Berechnung des Strahlungstransports mit dem Simulationsprogramm MODTRAN, das für die von CO2 verursachte Temperaturerhöhung seit Beginn der Industrialisierung 0.34°C liefert.
Interessantes Modell. Der Verlauf der grünen Kurve (Residuen) deutet allerdings auf Autokorrelation der Residuen hin, so dass die Standardfehler der mit nach der einfachen MEthode der kleinsten Quadrate geschätzten Regressionskoeffizienten verzerrt sind und die Signifikanztests und Konfidenzintervalle ihre Gültigkeit verlieren. Da es sich um ein Zeitreihenmodell handelt, liegt es nahe, das zu heilen, indem man eine über einen Monat hinausgehende Energiespeicherung der Erdoberfläche annimmt und zusätzlich den Regressor a[2]*T[i-2], – ggf wenn dann die Residuuen immer noch autokorreliert sein sollten, auch a[3]*T[i-3] – in die Gleichung aufnimmt. Das setzt natürlich voraus, dass die dahinterstehende Annahme einer über einen Monat hinausgehenden Energiespeicherung der Erdoberfläche sinnvoll ist.
Danke für den wichtigen Kommentar. Zunächst möchte ich darauf hinweisen, dass ich das Residuum geglättet hatte. Ich habe jetzt die Graphik ersetzt und in der vergrößerten Darstellung auch noch das unveränderte Residuum dargestellt.
Ihren Vorschlag, 2-3 Vormonate noch als Regressionsvariable dazu zu nehmen, hatte ich bereits in meinen Experimenten ausprobiert. Das „heilt“ allerdings das Problem der augenscheinlich systematischen Abweichungen des Residuums nicht. Sie müssen bedenken, dass mein Modell nicht ein Regressionsmodell vom Typ ARMA ist, sondern ein physikalisches Modell einer Differentialgleichung 1. Ordnung. Da ist implizit bereits die (exponentiell fallende) gewichtete Berücksichtigung der Vor-Vorgänger mit eingebaut.
Bis zum Erweis des Gegenteils gehe ich davon aus, dass die vom weißen Rauschen abweichenden Teile des Residuums der zeitlichen Auflösung geschuldet sind. Da der DWD keine tagesgenauen Daten für ganz Deutschland anbietet, ist es mir aktuell zu aufwendig, diese aus den Daten der einzelnen Meßstationen selbst zu berechnen — ich hätte das zusätzliche Problem, dass jeder die Qualität dieser Daten dann anzweifeln könnte. Aufgrund der großen Zahl der Meßpunkte ist die Normalverteilung bei der Schätzung der Parameter sehr wohl gegeben.
Vielen Dank für die Antwort, die Glättung des Residuums hatte ich übersehen/ -lesen. In der Tat, die ungeglätteten Residuen sehen ok aus. Ein einfacher, aber überzeugender Ansatz
Sehr geehrter Herr Dengler,
könnten Sie bitte die letzte Grafik auch von 1960 bis heute zeigen und darstellen, vielen Dank
beste Grüße
ist geschehen…