 von
von 
Der traditionelle Ansatz wird in Frage gestellt
Die Schlüsselfrage zum Klimawandel ist Wie stark beeinflusst der  -Gehalt der Atmosphäre die globale Durchschnittstemperatur? Und insbesondere, wie empfindlich reagiert die Temperatur auf Veränderungen der -Konzentration?
-Gehalt der Atmosphäre die globale Durchschnittstemperatur? Und insbesondere, wie empfindlich reagiert die Temperatur auf Veränderungen der -Konzentration?
Wir untersuchen dies anhand von zwei Datensätzen, dem HadCRUT4-Datensatz zur globalen Durchschnittstemperatur und dem CMIP6-Datensatz zum -Gehalt.
Die Korrelation zwischen diesen Daten ist ziemlich hoch, so dass es ziemlich offensichtlich erscheint, dass ein steigender -Gehalt steigende Temperaturen verursacht.
Mit einem linearen Modell scheint es einfach herauszufinden, wie genau die Temperaturen im Jahr i  durch den -Gehalt
durch den -Gehalt  und das zufällige (Gauß’sche) Rauschen
und das zufällige (Gauß’sche) Rauschen  vorhergesagt werden. Aus theoretischen Überlegungen (Strahlungsantrieb) ist es wahrscheinlich, dass das Modell mit
vorhergesagt werden. Aus theoretischen Überlegungen (Strahlungsantrieb) ist es wahrscheinlich, dass das Modell mit  am besten passt:
am besten passt: 
Die Konstanten a und b werden durch eine Anpassung mit der Methode der kleinsten Quadrate bestimmt (mit dem Python-Modul OLS aus dem Paket statsmodels.regression.linear_model):
a=-16,1, b=2,78
Daraus lässt sich die Sensitivität bestimmen, die als Temperaturdifferenz bei Verdopplung von definiert ist: °C = 1,93 °C
°C = 1,93 °C
Das sind fast 2 °C, eine Zahl, die nahe an den offiziellen Schätzungen des IPCC liegt.
Was ist daran falsch, es scheint sehr einfach und logisch zu sein?
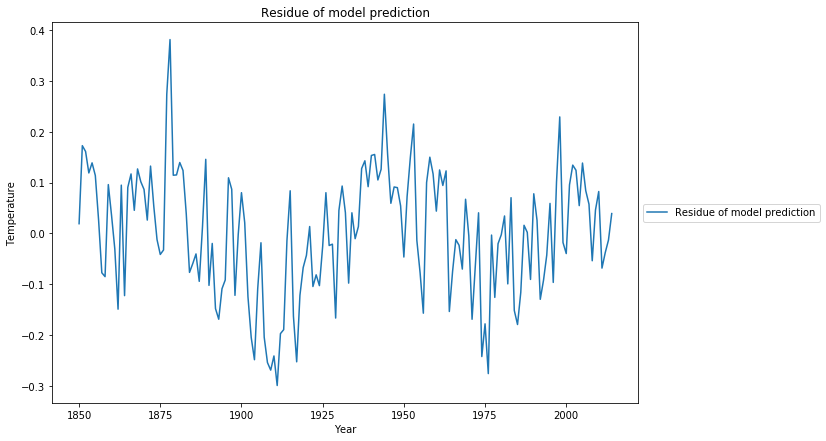
Wir haben das Residuum der Anpassung mit der Methode der kleinsten Quadrate noch nicht untersucht. Unser Modell besagt, dass das Residuum Gaußsches Rauschen sein muss, d.h. unkorreliert.
Der statistische Test, um dies zu messen, ist der Ljung-Box-Test. Betrachtet man das Q-Kriterium, so ist es Q = 184 mit p=0. Das bedeutet, dass der Residuum signifikante Korrelationen aufweist, es gibt strukturelle Informationen im Residuum, die mit dem vorgeschlagenen linearen Modell des log()-Gehalts nicht erfasst wurden. Ein Blick auf das Diagramm, das die angepasste Kurve zeigt, lässt erahnen, warum der statistische Test fehlgeschlagen ist:
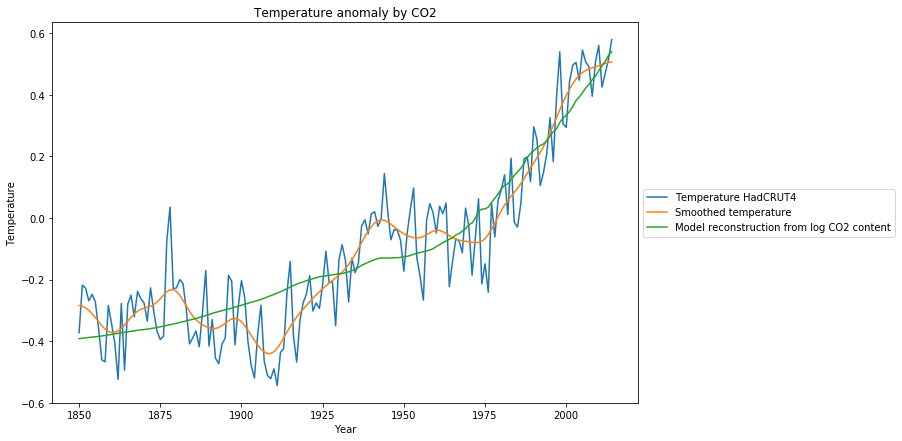
Wir sehen 3 Diagramme:
- Die gemessenen Temperaturanomalien (blau),
- die geglätteten Temperaturanomalien (orange),
- die Rekonstruktion der Temperaturanomalien basierend auf dem Modell (grün)
Während das Modell im Vergleich zu den verrauschten Originaldaten vernünftig aussieht, ist es aus den geglätteten Daten offensichtlich, dass es neben noch andere systematische Gründe für Temperaturänderungen geben muss, die vorübergehende Temperaturrückgänge wie während 1880-1910 oder 1950-1976 verursachen. Am überraschendsten ist, dass von 1977-2000 der Temperaturanstieg deutlich größer ist, als es das Modell des -Anstiegs erwarten ließe.
Die systematischen Modellabweichungen, u.a. ein 60-jähriges zyklisches Muster, sind auch zu beobachten, wenn man sich die Residuen der kleinsten Quadrate Schätzung anschaut:
Erweiterung des Modells mit einer einfachen Annahme
Angesichts der Tatsache, dass die Ozeane und bis zu einem gewissen Grad auch die Biosphäre enorme Wärmespeicher sind, die Wärme aufnehmen und wieder abgeben können, erweitern wir das Temperaturmodell um einen Speicherterm der Vergangenheit. Ohne den genauen Mechanismus zu kennen, können wir auf diese Weise die „natürliche Variabilität“ in das Modell einbeziehen. Vereinfacht ausgedrückt entspricht dies der Annahme: Die Temperatur in diesem Jahr ist ähnlich wie die Temperatur des letzten Jahres. Mathematisch wird dies durch einen erweiterten autoregressiven Prozess ARX(n) modelliert, wobei angenommen wird, dass die Temperatur im Jahr i eine Summe von
- einer linearen Funktion des Logarithmus des -Gehalts,log(), mit Offset a und Steigung b,
- einer gewichteten Summe der Temperatur der Vorjahre,
- zufälligem (Gauß’schem) Rauschen

Im einfachsten Fall ARX(1) erhalten wir

Mit den gegebenen Daten werden die Parameter geschätzt, wiederum mit dem Python-Modul OLS aus dem Paket statsmodels.regression.linear_model:
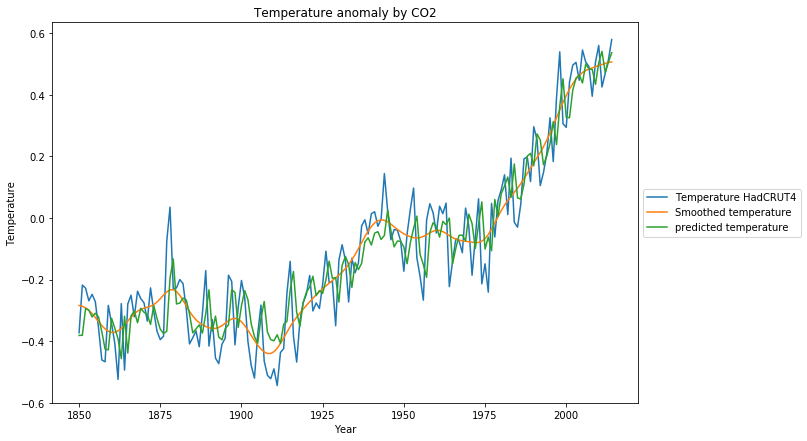
Die Rekonstruktion des Trainingsdatensatzes ist deutlich näher an den Originaldaten:
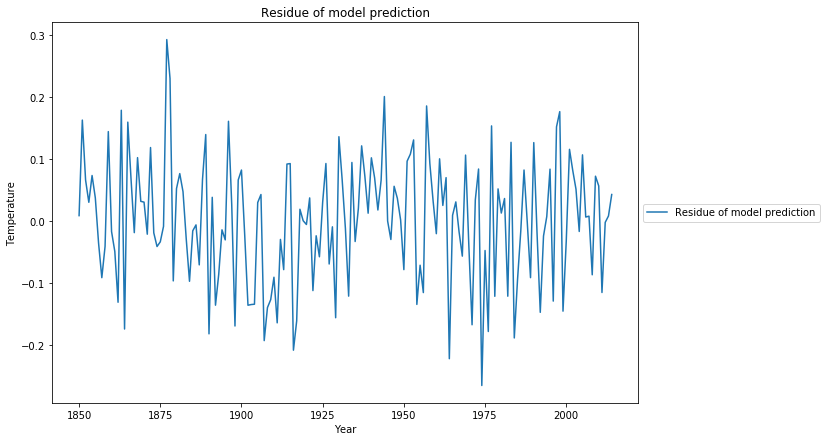
Das Residuum der Modellanpassung sieht nun viel mehr wie ein Zufallsprozess aus, was durch den Ljung-Box-Test mit Q=20,0 und p=0,22 bestätigt wird
Bei Berücksichtigung der natürlichen Variabilität reduziert sich die Empfindlichkeit gegenüber auf 
In einem anderen Beitrag haben wir die Abhängigkeit des atmosphärischen -Gehalts von den anthropogenen -Emissionen untersucht, und dies als Modell für Vorhersagen des zukünftigen atmosphärischen -Gehalts verwendet. Es werden u.a. 3 Szenarien untersucht:
- „Business as usual“ neu definiert anhand der neuesten Emissionsdaten als Einfrieren der globalen -Emissionen auf das Niveau von 2019 (was auch tatsächlich geschieht)
- 100% weltweite Dekarbonisierung bis 2050
- 50% weltweite Dekarbonisierung bis 2100
- 50% weltweite Dekarbonisierung bis 2050
- sofortige 50% weltweite Dekarbonisierung (hypothetisch)
Das resultierende atmosphärische wurde wie folgt berechnet, die statistischen Fehler sind so klein, dass die Prognose für die nächsten 200 Jahre sehr enge Fehlerintervalle aufweist.
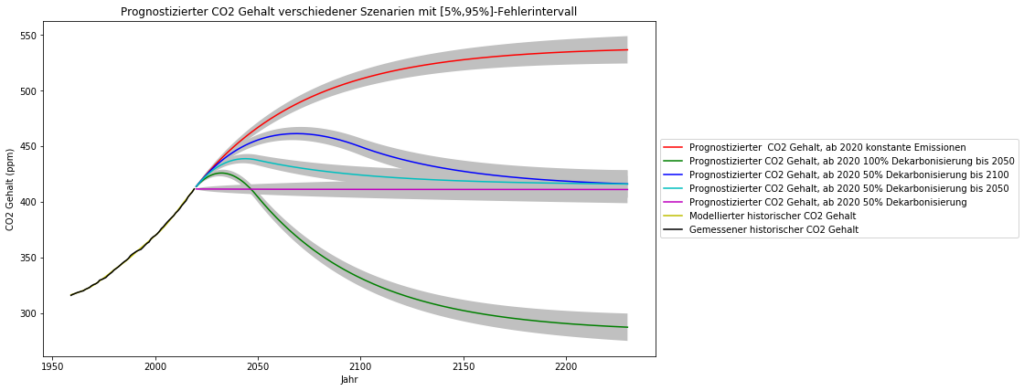
Füttert man das Temperatur-ARX(1)-Modell mit diesen vorhergesagten Zeitreihen des -Gehalts, so sind für die Zukunft folgende globale Temperaturentwicklungen zu erwarten:
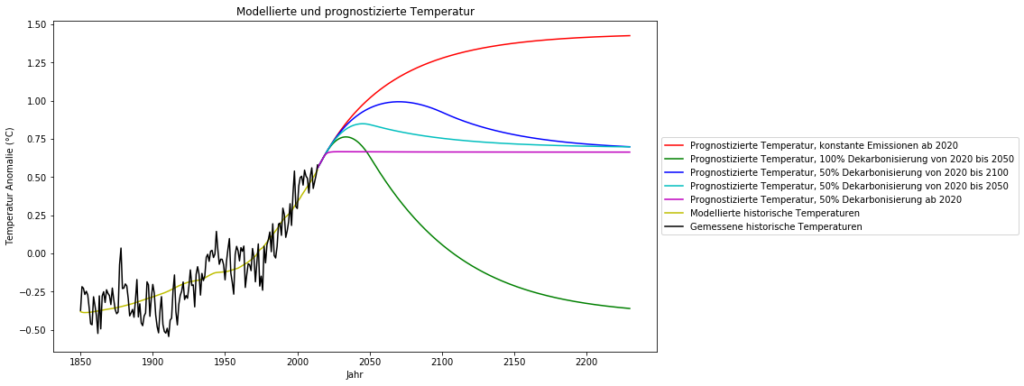
Schlussfolgerungen
Die folgenden Schlussfolgerungen werden unter der Annahme gezogen, dass es tatsächlich eine starke Abhängigkeit der globalen Temperatur vom atmosphärischen -Gehalt gibt. Ich bin mir bewusst, dass dies umstritten ist, und ich selbst habe an anderer Stelle argumentiert, dass die -Sensitivität bei nur 0,5°C liegt und dass der Einfluss der Wolkenalbedo viel größer ist als der von . Dennoch lohnt es sich, die Mainstream-Annahmen ernst zu nehmen und einen Blick auf das Ergebnis zu werfen.
Unter dem„business as usual“-Szenario, d.h. konstante -Emissionen auf dem Niveau von 2019, ist bis 2150 mit einem weiteren Temperaturanstieg um ca. 0,5°C zu rechnen. Das sind 1,4°C über dem vorindustriellen Niveau und damit unter der 1,5° C-Marke des Pariser Klimaabkommens.
Viel wahrscheinlicher und realistischer ist das Szenario „50%ige Dekarbonisierung bis 2100“ mit einem weiteren Anstieg um 0,25°C, gefolgt von einem Rückgang auf das heutige Temperaturniveau.
Die politisch propagierte „100%ige Dekarbonisierung bis 2050“, die nicht nur ohne wirtschaftlichen Zusammenbruch der meisten Industrieländer völlig undurchführbar ist, bringt uns zurück auf das kalte vorindustrielle Temperaturniveau, was nicht wünschenswert ist.