by
by 
The Vostok Ice core provides a more than 400000 year view into the climate history with several cycles between ice ages and warm periods.
It hat become clear that CO2 data are lagging temperature data by several centuries. One difficulty arises from the necessity that CO2 is measured in the gas bubbles whereas temperature is determined from a deuterium proxy in the ice. Therefore there is a different way of determining the age for the two parameters – for CO2 there is a “gas age”, whereas the temperature series is assigned an “ice age”. There are estimates of how much older the “ice age” is in comparison to the gas age. But there is uncertainty, so we will have to tune the relation between the two time scales.
Preprocessing the Vostok data sets
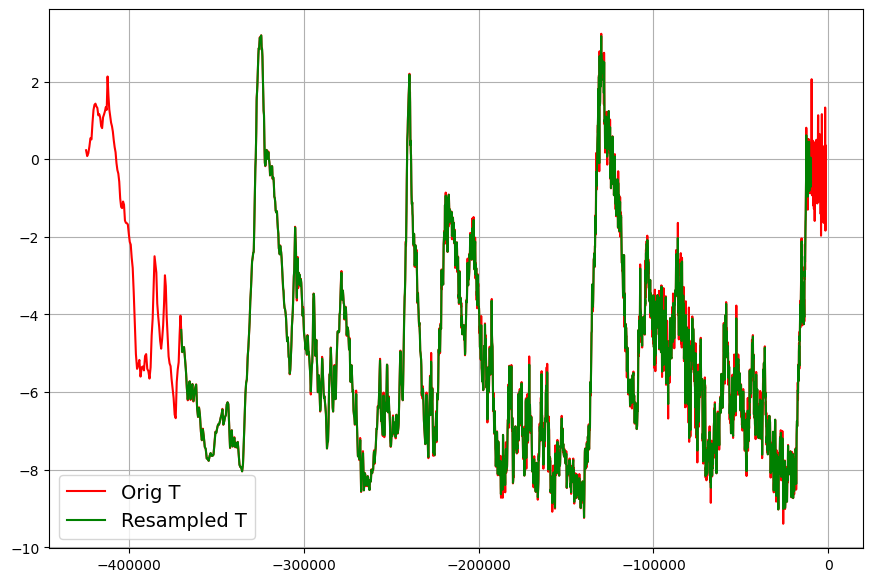
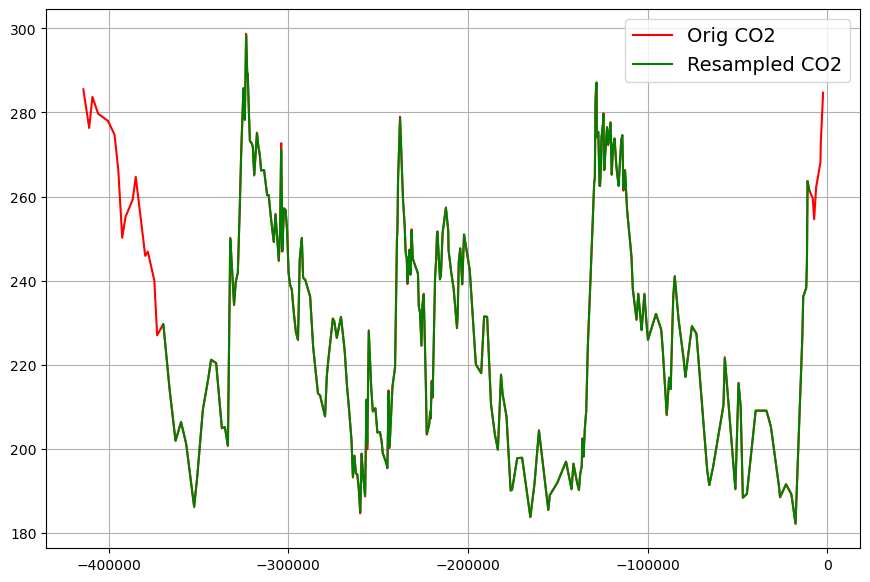
In order to perform model based computations with the two data sets, the original data must be converted into equally spacially sampled data sets. This is done by means of linear interpolation. The sampling interval is chosen 100 years, which is approximately the sampling interval of the temperature data. Apart from this, the data sets must be reversed, and the sign of the time axis must be set to negative values.
Here is the re-sampled temperature data set from -370000 years to -10000 years overlayed over the original temperature data:
And here the corresponding CO2-data set:
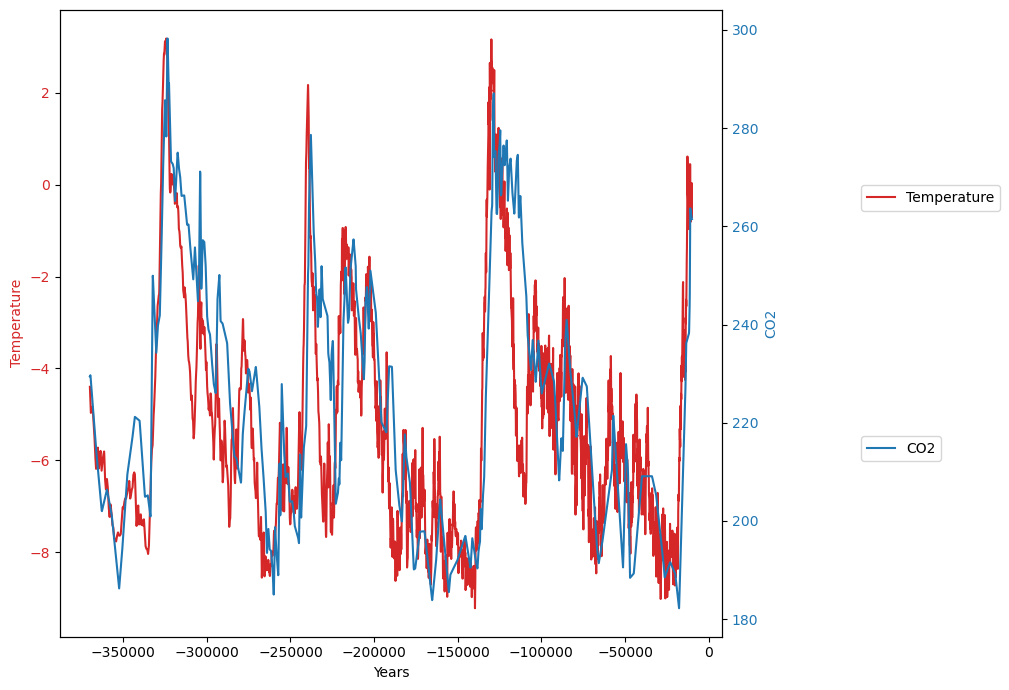
The two data sets are now superimposed:
Data model
Due to the fact of the very good predictive value of the temperature dependent sink model for current emission, concentration, and temperature data (equation 2) , we will use the same model based on CO2 mass balance, and possible linear dependence of CO2 changes on concentration and temperature, but obviously without the anthropogenic emissions. Also the time interval is no longer a single year, but a century.
G is growth of CO2-concentration C during century i:
is growth of CO2-concentration C during century i:

T is the average temperature during century i. The model equation without anthropogenic emissions is:

After estimating the 3 parameters x1, x2, and const from G, C, and T by means of ordinary least Squares, the modelled CO data
data  are recursively reconstructed by means of the model, the first actual concentration value of the data sequence
are recursively reconstructed by means of the model, the first actual concentration value of the data sequence  , and the temperature data:
, and the temperature data:

Results – reconstructed CO data
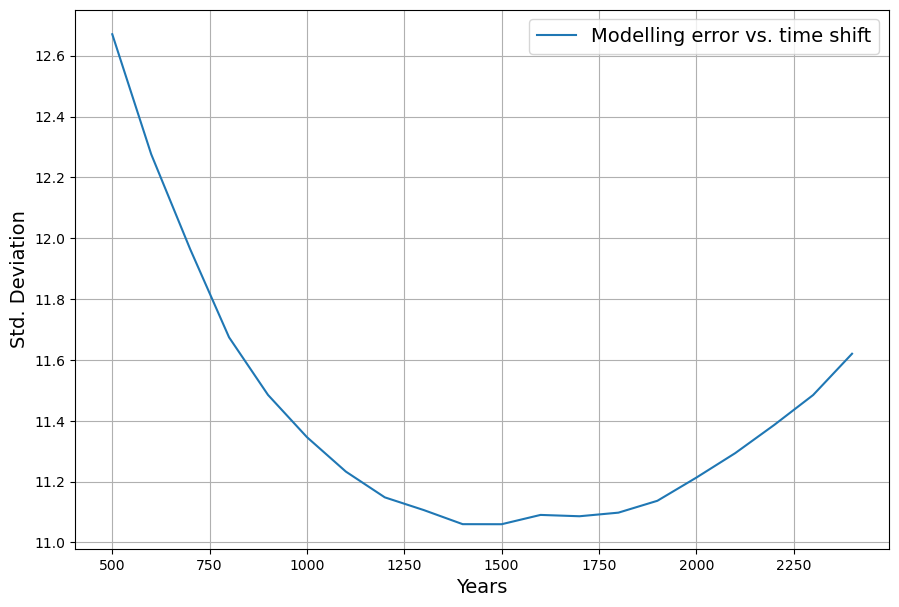
The standard deviation of  measures the quality of the reconstruction. Minimizing this standard deviation by shifting the temperature data is optimized, when the temperature data is shifted 1450..1500 years to the past:
measures the quality of the reconstruction. Minimizing this standard deviation by shifting the temperature data is optimized, when the temperature data is shifted 1450..1500 years to the past:
Here are the corresponding estimated model parameters and the statistical quality measures from the Python OLS package:
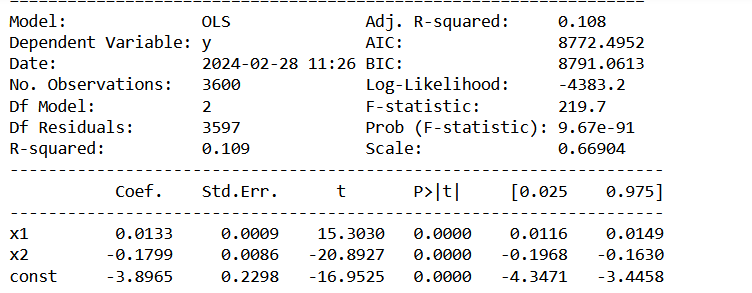
The interpretation is, that there is a carbon sink of 1.3% per century, and an emission increase of 0.18 ppm per century and 1 degree temperature increase.
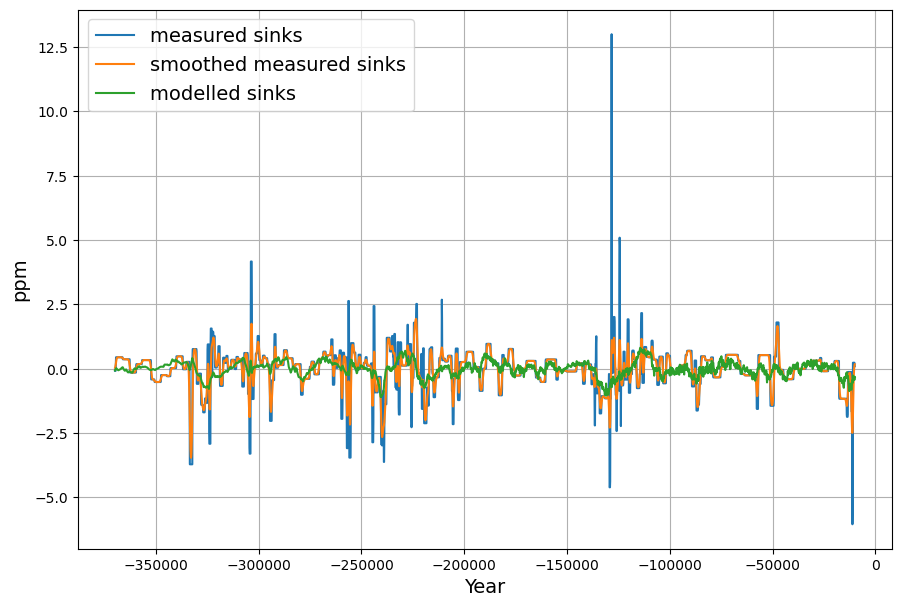
Modelling the sinks (-G) results in this diagram:
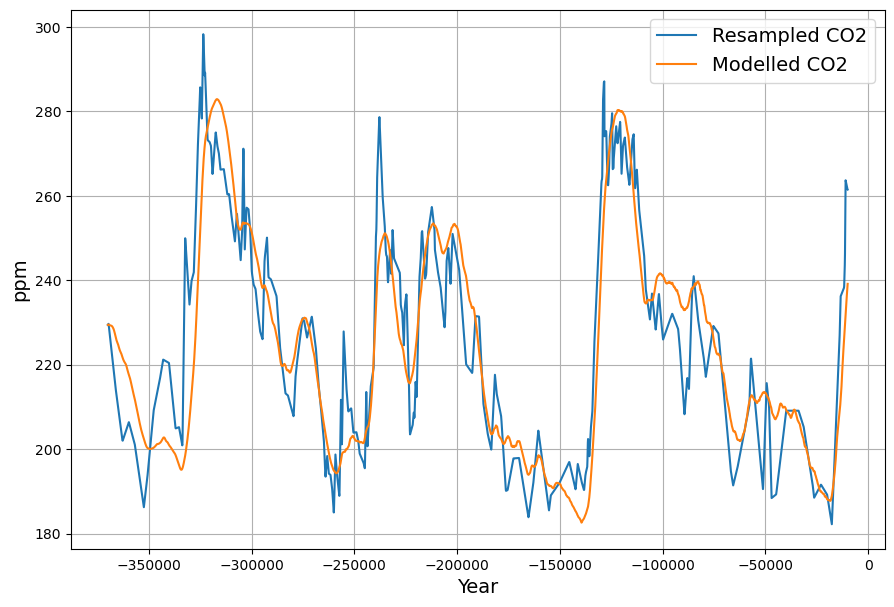
And the main result, the reconstruction of CO data from the temperature extended sink modell looks quite remarkable:
Equilibrium Relations
The equilibrium states are more meaningful than the incremental changes. The equlibrium is defined by equality of CO2 sources and sinks, resulting in  . This creates a linear relation between CO2 concentration C and Temperature T:
. This creates a linear relation between CO2 concentration C and Temperature T:
 ppm
ppm
For the temperature anomaly  we therefore get the CO2 concentration of
we therefore get the CO2 concentration of
 .
.
The difference of this to the modern data can be explained by different temperature references. Both levels are remarkably close, considering the very different environmental conditions.
And relative change is
This is considerably different from the modern data, where we got  .
.
There is no immediate explanation for this deviation. We need, however, consider the fact that we have time scale differences of at least 100 if not more. Therefore we can expect totally different mechanisms at work.